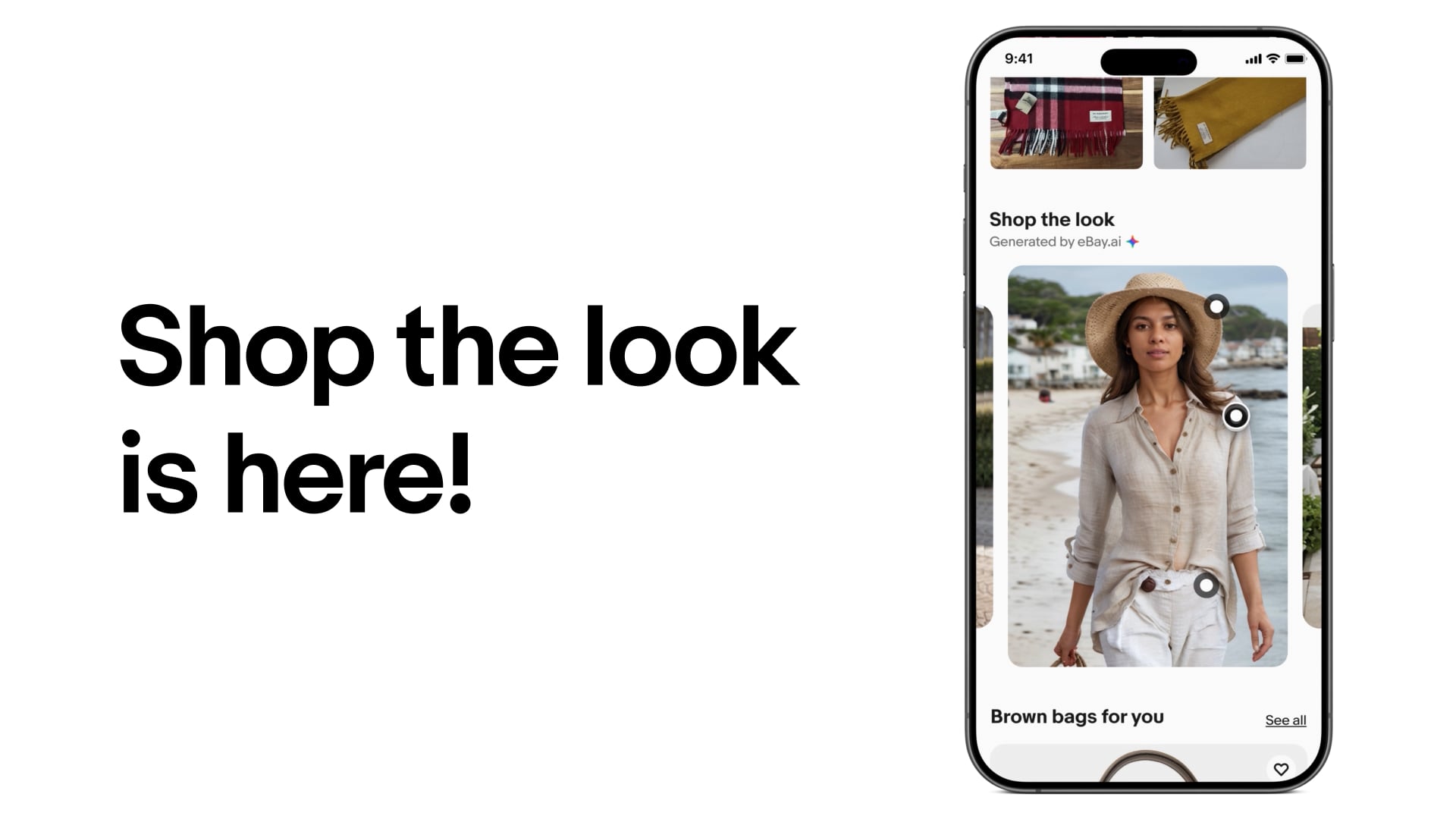
Powered by eBay.ai, fashion enthusiasts can now try a more personalized and exciting shopping experience.
We've adopted five guiding principles for the responsible use and development of AI.
Learn how eBay is deploying AI at scale to unlock employee productivity.
Hear from eBay's Chief AI Officer on a recent episode of the Bloomberg Intelligence podcast 'Tech Disruptors.'
Members of the winning team, NullPointer, will join eBay for a 2024 summer internship.
eBay's Lauren Wilcox named 2023 ACM Distinguished Member for contributions to responsible AI and human-centered computing.
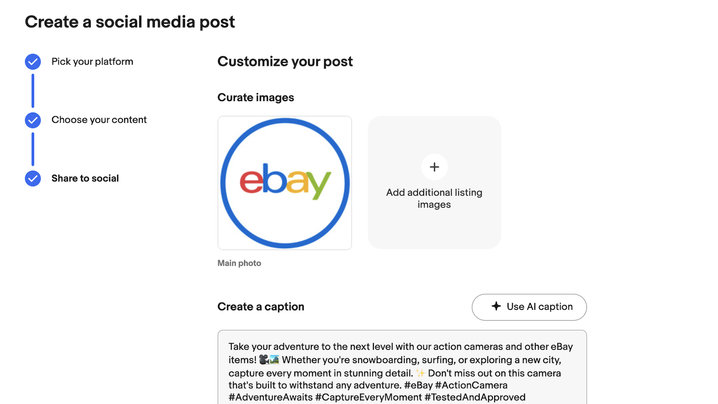
eBay sellers now have a new tool to make social sharing easier, all powered by AI.
Our goal: Help developers create better code, more efficiently, while maintaining accessibility for all.
By leveraging Apache Spark, eBay Graph Database can export a graph with billions of vertices and edges.
Nitzan’s work ensures that eBay can magically and responsibly deliver AI-powered experiences.